RSpec And The Uncanny Valley
Panda Strike favors assert-flavor TDD over the should and expect styles of BDD. There’s an important reason, and the best way to understand it is to look at an unusual but recurrent failing in programming language design.
OS X machines have a scripting language called AppleScript. It allows you to parse English text by writing English text. An example from Daring Fireball:
During AppleScript’s development, there was also a “Professional” dialect (for developers). You could rephrase the above line and have it look more like code:
But this never made it to release. Instead, AppleScript’s syntax is all about a limited and occasionally weird subset of English. It’s an interesting language. Here’s a few more snippets from Daring Fireball.
A sentence from the same post:
AppleScript gets a rap for being easy-to-read, but hard-to-write.
RSpec, Cucumber, Chai.js’s BDD mode, Jasmine, and BDD frameworks generally all have this same reputation. They’re all easier to read than they are to write. Not coincidentally, the BDD style revolves around making code look like English. Making code look like English is much, much easier than making code work like English.
With BDD tools, you’ll often spend a lot of time figuring out dinky, inconsequential details like “was it expect :to or expect().to”? Either one is equally easy to read, but (for example) RSpec values making its Ruby flow like English, when you read it, over making its Ruby flow like Ruby, when you write it. This leads to a lot of tiny inconsistencies which are hard to understand. Where, with a language like Ruby, you can mostly just remember general principles, with a DSL like RSpec, you have to memorize specifics.
I’m using a Ruby example here because I’ve got a strong Ruby background, but you see similar effects in BDD libraries for JavaScript, and of course in AppleScript as well. Some notes on AppleScript’s history:
AppleScript… was never loved by anyone. It was a fine theory and noble experiment, but it turns out that an English-like programming language didn’t really enable a large number of users to become programmers. And conversely, AppleScript’s English-like syntax often made (and to this day continues to make) things more difficult and confusing for scripters, not less.
I’d argue that you see this same “English but not” problem with BDD tools, and probably anywhere else a naïve language designer failed to examine the existing history and literature on the subject. “English but not” is always a pain in the ass, and I think it’s pretty safe to say that if you took the same approach in Spanish or Mandarin, you’d encounter similar frustrations.
The problem is the same problem as the uncanny valley, a phenomenon in animation and robotics where things which copy humans too closely, but imperfectly, can enter a kind of creepiness zone which you will never encounter if you instead mimic human behavior in a stylized, obviously fake way. This blog post has an apt illustration:
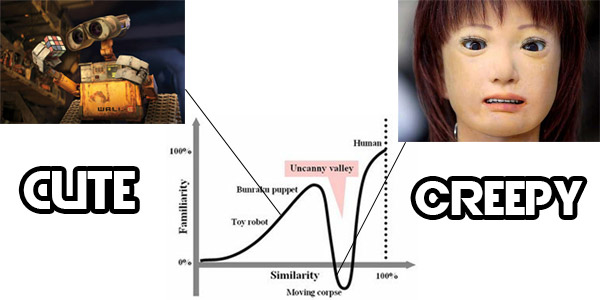
A robot which acknowledges its own artifice, but has stylized suggestions of human features, seems much more human than a robot which aims to ape humanity, but which nonetheless displays countless signs of its artificial nature. Likewise, a programming language which pretends to be a human spoken and/or written language often provokes a very jarring reaction, due to all the stiffness and artifice which shows up beneath its allegedly organic surface.
In addition to the general uncanny valley problem which plagues so many BDD tools, RSpec specifically has a bludgeon problem.
When pondering such things, it can be helpful to come at it from a tactile perspective. Sure, there are tools like
flogandsaikurothat can give you all kinds of numbers about a piece of code, but sometimes you just want to know, “What would this code be like if I printed it all out and picked it up?” You can imagine the smell of freshly printed pages and think to yourself, “How would it feel to heft it from hand to hand?” or “Would I be able to bludgeon someone to death with it?”I can’t help you with the first two questions, but I wrote a library specially designed to answer the last:
Bludgeon is a tool which will tell you if a given library is so large that you could bludgeon someone to death with a printout of it.
If you gem install bludgeon and let Bludgeon work its magic, it’ll tell you, yes, the RSpec code base is so big you could literally bludgeon someone to death with it, if you printed it out on paper.
This is because if you want to make a DSL easy to read as if it were English, even though it is not easy to write in the same way, you will have to build enormous and complex machinery.
Ironically, if you’re trying to write code which reads as if it were English, you’ll have the least errors if you understand how all that complex machinery works under the hood. But if you have to memorize internals to get your high-level API to look elegant, odds are not good that this API will also actually be elegant. DSLs are useful and valuable, but like anything else in programming, they come with tradeoffs attached, and you have to choose wisely.
Consider Cucumber’s regexes. Any time you find yourself writing regular expressions to parse the English language, you have to question that decision, and re-examine your motives and your strategy.
As far as I can tell, a major strength BDD evangelists claim, when they advocate tools like RSpec and Cucumber, is that the tools produce output which is readable to people on your team who are not programmers. In practice, that doesn’t seem to happen. In my experience, nobody ever shows RSpec or Cucumber output to people on the team who aren’t programmers, because if you do, this is the reaction you get:

Awkward silence is another common reaction when you show a non-technical business person Cucumber output. Or, when you say “now all you have to do is run this code and you can see how many features we’ve implemented!” they may ask you how to run the code. If you show them how to run the code, you also have to show them how to update the repo. If you show them how to update the repo, you may have to show them how to update the dependencies as well. BDD tools for non-technical people seem most useful when a technical person runs them on his or her computer.
The uncanny valley produces very unsettling effects in animation and robotics, but in programming, its results are more just aggravating and slightly paralyzing. Unit tests are already fairly prone to technical debt, and a really quirky syntax which relies on memorizing specifics, rather than understanding general principles, increases that risk. It doesn’t make sense to be increasing your risk of technical debt just to make code easier to read for people who are never going to read it. Making it harder to write for the same reason is likewise illogical.
If you’ve got a massive investment in a BDD tool already, this isn’t necessarily a reason to throw all that code out the window immediately. But it is a good reason to be cautious about building up that kind of investment in the first place.