Blog
Our most recent posts are below. You can also check out our greatest hits or most popular.
EU DMA Is For Real

When the EU’s DMA and its cousin, the DSA, passed in 2022, I was surprised.
CISA Open Source Safety Analysis

The US cybersecurity agency analyzed popular open-source projects and found that many widely used projects still contain a lot of unsafe code.
RIAA Sues AI Music Companies

The RIAA joins the New York Times in claiming that training LLMs does not constitute “fair use.”
InterOp 2024
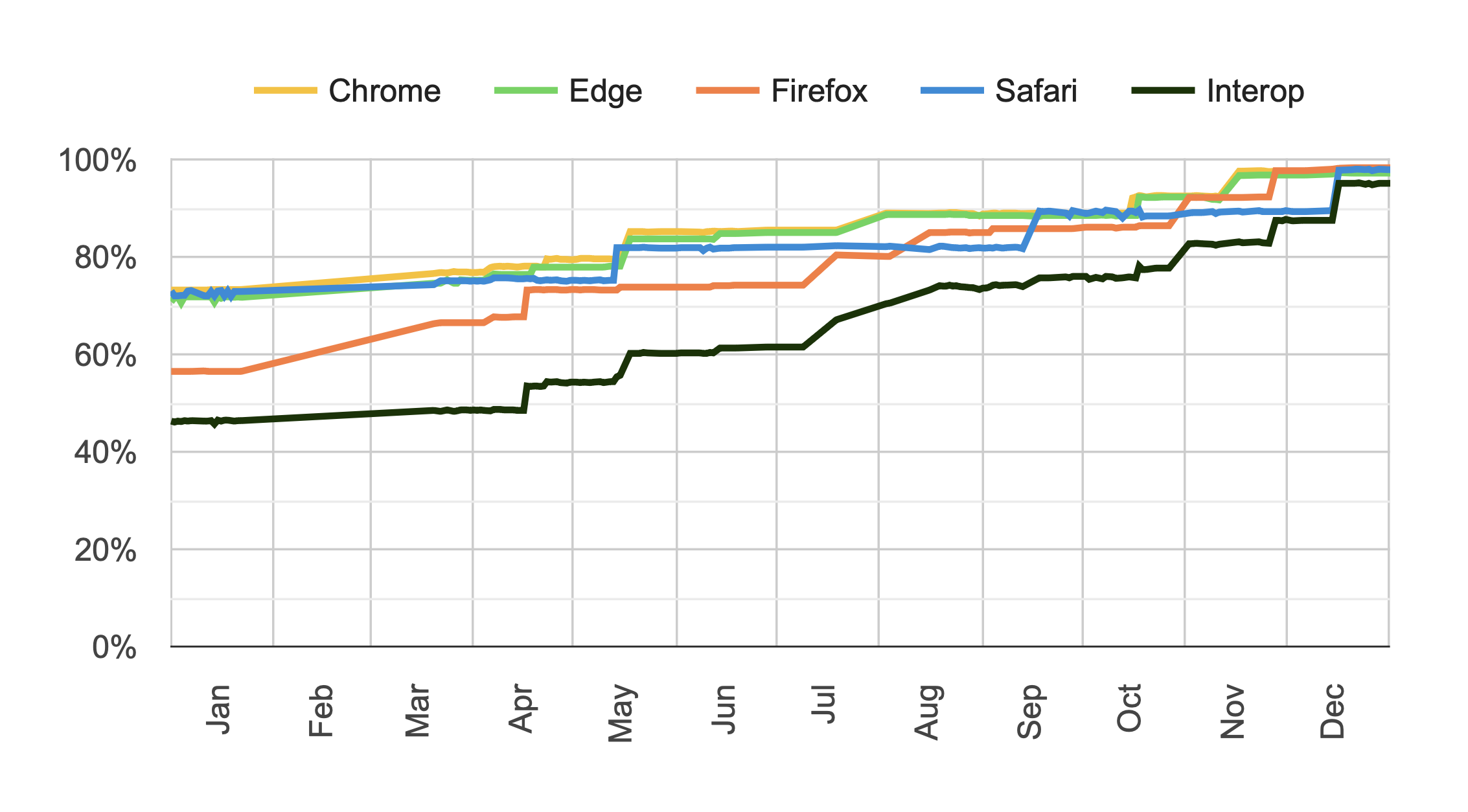
InterOp has led to a tremendous improvement in browser interoperability, particularly with newer features. So it’s great that they’ve set new goals for 2024.
Announcing Graphite - Our New Cloud Graph Database Technology

I am very excited to announce [Graphite][], our serverless graph database technology, which we developed with one of our clients and can now share with you. In fact, we’re so excited about this technology, we’re shifting our focus to helping clients leverage it.
Panda Sky 2.6 - Introducing Self-Assembling Clients For HTTP APIs

Today I’m excited to introduce the Sky client, making it easy to integrate with any Sky API you build. I’m also announcing Panda Sky v2.6, featuring a couple new command line features to help with testing.
Panda Sky 2.5 - Log Tailing for Sky Deployments

Sky 2.5 introduces a new, handy feature: log tailing. You can now look at your entire deployment’s log trace from the comfort of your own terminal.
Panda Sky 2.4 - Introducing Sky Mixins and a Sundog Preview

Happy New Year! I’m proud to announce Sky v2.4. This version includes support for mixins - entities that extend Sky’s deployment and command line features. This post will show you what kind of features are now available, as well as a preview of Sundog, a new project aiming to be a functional version of the AWS SDK.
Functional Mixins In JavaScript

Mixins add behavior to a type (or class) without relying on inheritance. JavaScript has nice prototype-based types and recently added classes, but lacks first-class mixins. Fortunately, it provides everything we need to implement them. Since we use mixins for Play, our library for creating native Web Components, I thought I’d share our approach here.
Introducing Panda Sky, Severless APIs Made Easy

We are really excited by the potential of serverless architectures to provide a simpler and more reliable way to deploy modern Web and mobile apps. However, serverless is still relatively new, and, like any new technology, it can be difficult to workt with. We wanted to make it easier, so we built Panda Sky.
Introducing Play, A React-Like Web Components Library

We’ve been fans of Web Components since they were first announced. We had the opportunity to experiment with them, and with Polymer, in particular. But we were frankly disappointed in the results. Our team, like many developers, found React, and React-inspired frameworks easier to use. What was missing was the simplicity of React, but for Web Components. So I built it.
Padding Blocks with PyCrypto in Google App Engine

Assume (for the sake of argument; no need to tell us why) that one day you find yourself working with Python in Google App Engine, using PyCrypto to encrypt secrets. Unless your plaintexts are always a multiple of 16 bytes in length, you are likely to run into this error:
ValueError: Input strings must be a multiple of 16 in lengthThe answer is to pad out your plaintext to an appropriate length, but the version of PyCrypto available in App Engine can’t do this for you.
Your Password Policy Is Wrong

Earlier this year, I received an email from LifeLock warning of the ills of weak passwords. Unfortunately, the folks at LifeLock don’t appear to be experts in effective password strength policies. I want to address the following statement specifically:
[Use] upper- and lower-case letters, special characters and numbers. And make sure the resulting passwords aren’t words found in the dictionary.
In the words of Dwight Schrute: WRONG. In fact, the best method we have for generating strong passphrases—called Diceware—relies on randomly-selected dictionary words.
Google Fiber Is A Death Star

Google Fiber’s big announcement last week, that they’re going to “pause” the rollout of Google Fiber in new cities, in combination with the resignation of CEO Craig Barratt, led to a lot of speculation that this particular letter in the Alphabet is in trouble. Everyone from Ars Technica to The Washington Post had some fun with this story. We offer a contrarian take.
Google Fiber isn’t in trouble: in fact, it’s poised to completely disrupt the ISP market. In short, Google Fiber is a Death Star.
Do IoT Botnet DDoS Attacks Threaten The Internet?

The following is an edited transcript of an internal Panda Strike Slack discussion, in which we assess implications of the recent IoT-based DDoS attack and conclude that we need to drink delicious beer.
Dan So the Internets are freaking out today about how people’s toasters have become an attack vector.
Soft Deletes In HTTP APIs

A fun question came up the other day on our internal Slack channel:
For soft-deletes (where we keep a record in the database, but set a flag that it’s been deleted), we’re trying to decide between
DELETEorPUTwith a body{status: 'deleted'}. That way, we can reserveDELETEfor hard deletes. Any recommendations?Yes, we’ve got recommendations, but they might surprise you.
Visualizing Distributed Load Tests With JMeter, Elasticsearch, Fluentd, and Kibana
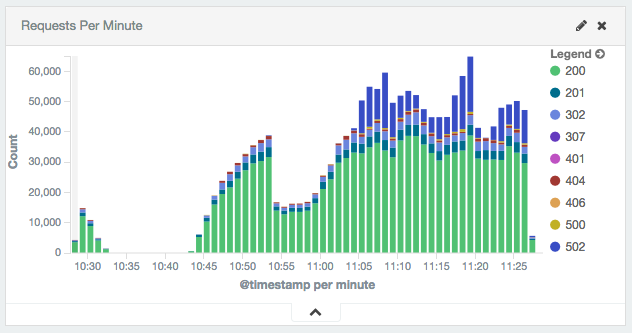
Apache JMeter is a flexible tool for producing load against an application and measuring the results. We used it on a recent project to measure performance of a large and complex web site. The results of the performance tests required aggregation and visualization.
JMeter has its own built-in distributed performance testing capability. It also has the capability to visualize the test results. We found both lacking.
Version Media Types, Not URLs

Roy Fielding’s advice on versioning APIs is, well, succinct:
In a subsequent interview, he elaborates:
Websites don’t come with version numbers attached because they never need to.
Neither should a RESTful API.
Microservices And Serverless Architecture

One of our favorite patterns at Panda Strike is to have an HTTP API that dispatches jobs to workers. We called this the dispatcher-worker pattern, but its names are exceeded only by its variations. In particular, it’s a variation of the microservices pattern.
So you can imagine our excitement about Amazon’s support for “serverless” architecture, which happens to fit this pattern perfectly.
Design Patterns In HTTP

We’ve made the case on this blog that REST is the wrong way to try and understand HTTP. We’ve also said that it’s worthy of study if only because the Web runs over HTTP. We’ve even contributed a few introductory blog posts to the subject.
But that begs the question—what’s the big picture here? Is HTTP’s success due to the Web or is it the other way around? Is there some brilliant insight that HTTP captures or is Fielding’s dissertation on REST, which he didn’t expect anyone to read (pretty typical for a dissertation), the best we can hope for?
SpaceX Wallpaper From Unsplash.com

I am a fan of SpaceX and the work that they are doing to get the human race to Mars and beyond. I am also a fan of having new desktop wallpapers. Browsing the web I saw a link to SpaceX’s unsplash.com profile, and instantly wanted their incredible photos as my desktop wallpaper. My goal was to always have the latest photo without constantly checking the Unsplash profile. So, I put my computer to work.
You Can't Turn The Network Invisible
Last year, Jafar Husain gave a presentation about Falcor and how Falcor has changed how Netflix handles it APIs. Falcor, like Relay, is a clever bit of programming with an alluring promise to simplify network programming via a powerful abstraction. But we’ve already followed this seductive sirens’ song, many times before, and it usually doesn’t end well.
Creating SSL Certs For Amazon API Gateway Using ZeroSSL And Let's Encrypt
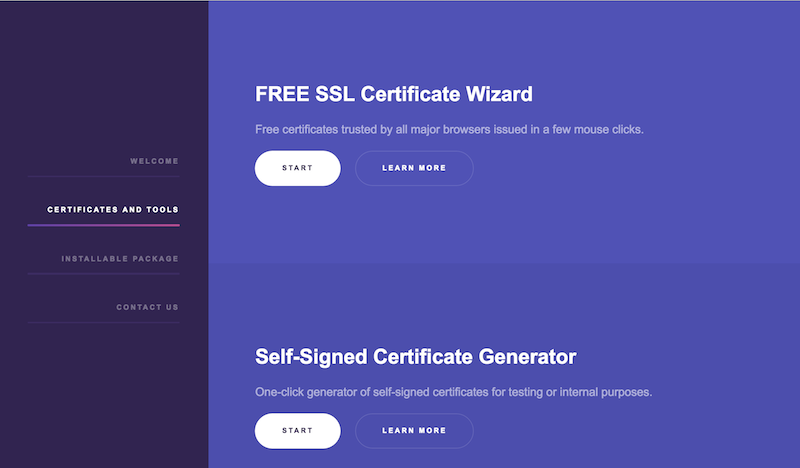
Let’s Encrypt is a free Certificate Authority for TLS, which we believe is a crucial advance for the Open Web. ZeroSSL takes the great work Let’s Encrypt is doing one step farther, by making it easier to create LE certs. So there’s more reason than ever to protect your Web sites or apps with TLS. In this post, we’re going to walk you through using ZeroSSL to generate a cert for Amazon’s API Gateway service. And you won’t need to install a thing!
Anywhere Is Everywhere

The following is an excerpt from our upcoming book about remote work, The Global Office.
Success stories for remote work are common in the software business. The Linux operating system was developed via remote collaboration, along with all its various distributions, and thousands of other open source software libraries. There’s GitHub and Basecamp (formerly 37Signals) and dozens of lesser known but successful software companies, all of whom work remotely.
HTTP Is The New Lisp

This is Greenspun’s Tenth Rule:
Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.
You can tell how old it is by the fact that C and Fortran are given as examples of popular languages. We don’t personally know this Greenspun person, but let’s just assume he hung out with Ada and Alan back in the day.
Machine Learning And Big Data Is All Just Fun And Games

Analytics and machine learning are increasingly relevant tools in the software professional’s toolbox. Statistics and probability now play a greater role than ever in our work.
Games can be a fun “gateway drug” for learning these techniques. In particular, the sports industry has recently turned to mathematics in the quest to gain a competitive advantage. Organizations like FiveThirtyEight, originally known for using polling data to make predictions about political races, now routinely predict outcomes for sporting events based on performance models and historical data.
Facebook React And A Party Gone Wrong: A Socractic Dialog

Recent buzz about Facebook React—I guess there was a conference or an announcement or something?—inspired an internal discussion here at Panda Strike. We’re on the record as not being big fans of the framework, but, as a group of smart, spirited software professionals, we sometimes disagree. Our respective opinions on Facebook React, and possibly many other things, may differ from those expressed on our blog. Which is fantastic. In fact, we’re hoping to bring more of those voices to the blog.
More Agile Than Agile Itself
One of the big ironies of the discussion around remote work is that some Agile gurus have said that remote work is incompatible with Agile development. This couldn’t be more false.
The truth is precisely the opposite: remote work is inherently more Agile than any Agile development methodology.
Examples of using Blocks in Ansible 2
Docker Swarm With AWS VPC

Docker offers a feature rich platform for Linux containers. Amazon Web Services offers a feature rich platform for cloud computing. Naturally, we want to use them together. In particular, we want to use Docker Swarm running within an AWS VPC. Unfortunately, this isn’t quite as easy as you might think. Here’s our solution.
Introducing YAML-CLI: A YAML Command Line Processor

YAML is our favorite data format. Well, it’s my favorite data format, anyway. Popularized by Ruby and Rails, YAML is powerful and expressive. Consequently, it’s seeing increasing adoption, everywhere from dev ops tools, such as Docker or Ansible, to static site generators.
So it was surprising to discover the relative paucity of tools for processing YAML from the command-line. The few that do exist didn’t meet our needs, so we wrote our own.
HTTP And The Zombie Apocalypse

HTTP is the world’s most successful application protocol. Yet it is widely maligned and misunderstood. Part of the problem is a poor developer experience. Part of the problem is that a Ph.D. dissertation is usually not the best introduction to a subject. And part of the problem is that building network applications is hard and we blame HTTP for that when we shouldn’t.
REST Won't Help You Understand HTTP

The HTTP protocol gets a bad rap. HTTP is simply an application protocol that provides a well-considered set of features for distributed applications. Naming, caching, compression, and so forth, are not superfluous complications introduced by HTTP. They’re just things distributed applications need to do. HTTP is annoying because distributed computing is annoying.
The Four Keys When Hiring Remote

Hiring is hard. Hiring technical people well is harder. Hiring technical people that work remotely is even harder. To be good at it, you need to already be good at hiring. You can build on that to become good at hiring remote workers.
Embracing remote work means hiring from a larger pool of talent. But it also requires being more selective— you only want to consider people who will be successful working remotely. Assuming that you have a high success rate with your existing hiring process, here’s how you can ensure it stays that way when hiring remote workers.
Remote Work's Greatest Challenge

We’re working on a book about remote work. One of our goals is to honestly discuss the challenges in working remotely. We’ve already written about some of them. You may have to change the way you think about managing. You may need to get better at assessing your team’s productivity. You probably will need to adapt your development process. Our upcoming book will dive into these in more detail. But there’s one challenge that I believe is the biggest of them all. And it’s one we haven’t written about, until now.
Brave Is Interesting But Ad-Blockers Are Better For The Web
Brendan Eich’s latest venture is [Brave][], a browser platform that blocks ads and trackers while encouraging people to pay for content. Brendan has done a lot for the Open Web, founding Mozilla at a time when Microsoft was threatening to turn the Web into a proprietary technology, and working all the while [to improve JavaScript][]. And I don’t doubt that his latest venture [is equally well-intentioned]… [Brave]:https://brave.com [to improve JavaScript]:https://www.pandastrike.com/posts/20151105-in-defense-of-javascript [is equally well-intentioned]:https://brave.com/index.html#about
Announcement: We're Writing The Book On Remote Work

As you may know, Panda Strike is a 100% remote work company. We’ve been so since we started back in 2012. During the past couple of years, we noticed that interest in remote work appears to be increasing. So we thought we’d share what we’ve learned in an ebook on the subject, which we plan on making available in February. Join our mailing list and we’ll let you know when it’s ready.
Paywalls Are Not The Answer

Troy Hunt recently wrote a blog post with the wonderfully descriptive title, It’s 2016 already, how are websites still screwing up these user experiences?!. Many of the problems Mr.Hunt describes are manifestations of content producers inability to figure out how to make money.
On the one hand, if you’re selling ads, you can end up crossing this weird line where you’re basically telling your readers that you don’t really want them to read your articles. You simply want them to click on an ad. Your content has become subordinate to the ads. Is that really what you wanted?
Risk And Uncertainty In Estimating Software Projects
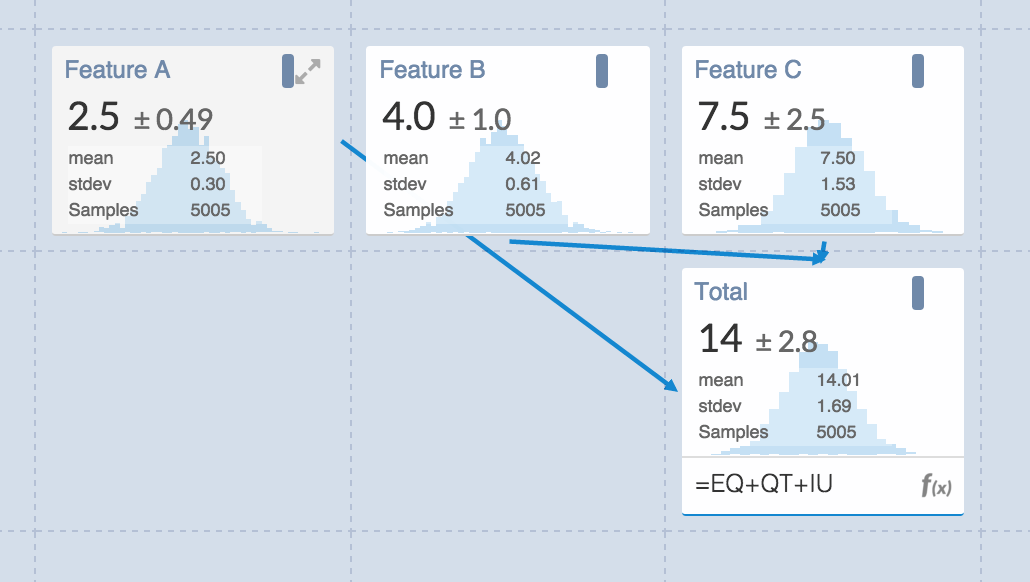
Estimating the cost and duration of software projects is, apparently, a hard problem. Thus, Hofstadter’s Law:
It always takes longer than you expect, even when you take into account Hofstadter’s Law.
I was reminded of this, and inspired to write this blog post, when I saw an Web app pop up in my Twitter feed. It’s called Guesstimate and it describes itself as “a spreadsheet for things that are uncertain.” There’s even a blog post explaining the idea. It’s a fantastic way to explore the impact even small amounts of uncertainty can have on costs.
2015 In Review: 7 Tech Truth Bombs

As 2015 comes to a close, I thought it would be fun to share a few of our big take-aways. Can you handle the truth?
Well, okay, then.
Without further ado, here are 7 truth bombs about the tech industry in 2015.
Your Official 2015 Panda Strike Holiday Reading Guide

If you’re looking for some holiday reading, look no further! We’re here to help. We did a lot of blogging this past year, Relatively speaking anyway. and odds are that you missed a post or two, so here’s summary of what we wrote about in 2015.
